[ 1과목, 소프트웨어 설계 ]
■ 시스템의 구성요소 : 입력(Input), 처리(Process), 출력(Output), 제어(Control), 피드백(Feedback)
■ Feedback : UI와 관련된 기본 개념 중 하나, 사용자가 내용을 해석할 수 있도록 도와주는 것
■ 요구사항 개발 과정 : 도출 → 분석 → 명세 → 확인(검증)
■ 요구사항
- 기능 요구사항 : 기능
- 비기능 요구사항 : 성능, 품질, 제약 조건
■ UI 설계 도구와 연관된 모형 (실제구현x)
- 목업 (Mockup) : 정적 (실제 화면과 유사)
- 프로토타입 (Prototype) : 동적 (테스트 가능)
■ 특별한 조건을 만족할 때 수행하는 유스케이스 : 확장 관계 <<extends>>
■ 모델(Model) : 향후 개발될 시스템의 유추 가능, 뷰(View)와 직접 연결x
■ 다형성(Polymorphism)
- 메소드 오버로딩(Overloading) : 메소드명 같게, 매개 변수 타입 다르게
■ 익스트림 프로그래밍(Extreme Programming, XP)
- 소규모 개발 조직에 적합, 불확실하고 변경이 많은 요구를 접하였을 때 적절한 방법
- 개발 문서보다 소스코드에 중점을 둠
- 구동원리 : 상식적인 원리(피존의 용기)와 경험을 최대한 끌어 올리는 것
- 대표적인 애자일(Agile) 개발 방법론 중 하나 (구조방법론x)
■ 마스터-슬레이브 아키텍처(Master-Slave Architecture)
- 주(master)와 종속(slave) 시스템 간의 관계를 정의 (실시간)
- 마스터 : 슬레이브를 제어
- 슬레이브 : 마스터 지시 따름 (데이터 처리)
■ Entity-Relationship Diagram : 정보공학 방법론에서 데이터베이스 설계의 표현으로 사용하는 모델링 언어
■ 럼바우(Rumbaugh)의 객체지향 분석 기법
- 객체모델링 = ERD(Entity-Relationship Diagram), 정보 모델링, 시스템에서 요구
- 동적모델링 = 상태 다이어그램, 제어, 흐름, 동작
- 기능 모델링 = 자료흐름도( DFD )
■ 자료 흐름도(DFD) 주요 표기형태

■ 메시지 지향 미들웨어(Message-Oriented Middleware, MOM)
- 실시간 응답보다는 안정성 우선
- 비동기 방식 지원 (필요한 시점에 전송가능)
- 메시지 큐(Message Queue) 활용 가능: 송신자가 메시지를 큐에 넣으면, 수신자가 적절한 시점에 메시지를 가져가는 방식.
- 예시
1) ORB(Object Request Broker) : 코바(CORBA) 표준 스펙을 구현한 객체 지향 미들웨어
2) DB 미들웨어: 원격 데이터베이스와 연결할 수 있도록 벤더가 제공하는 클라이언트 미들웨어
■ MOM 주요 모델
(1) 퍼블리셔-서브스크라이버(Pub-Sub) 모델
- 메시지를 발행하는 퍼블리셔와 이를 구독하는 서브스크라이버가 존재
- 여러 개의 수신자가 동일한 메시지를 받을 수 있음
(2) 포인트-투-포인트(Point-to-Point) 모델
- 한 개의 송신자가 한 개의 수신자에게 직접 메시지를 전달 ( 메시지가 한 번만 소비됨 )
■ 오류 종류
- Transcription Error(필사 오류): 임의의 한 자리를 잘못 기입
- Addtion Error(추가 오류): 한 자리를 더 추가하여 잘못 기입
- Omission Error(생략 오류): 한 자리를 생략하여 잘못 기입
■ 요구사항 모델링: 애자일(Agile) 방법, 유스케이스 다이어그램, 시퀀스 다이어그램
■ UML의 기본 구성요소: 사물(Things), 관계(Relationship), 다이어그램(Diagram)
★암기 Tip★ 뒷(Things) 다(Diagram) 리(Relationship)
■ 자료사전(Data Dictionary)
= 정의
+ 구성
[] 택일
{} 반복
() 생략가능
** 설명
■ HIPO(Hierarchy Input Process Output) : 하향식
■ GoF(Gang of Four)의 디자인 패턴
(1) 생성 패턴 : Abstart Factory, FactoryMethod, Builder, Prototype, Singleton
(2) 구조 패턴 : Adapter, Bridge, Composite, Decorator, Facade(파사드), Flyweight(플라이웨이트), Proxy
(3) 행위 패턴 : Chain of Respon
sibility, Command, Interpreter, Iterator, Mediator, Memento(메멘토), Observer, State, Strategy, Template Method, Visitor
■ 시스템 품질속성 : 가용성, 변경용이성, 성능, 보안성, 사용편의성, 시험용이성 >> 독립성은 X
■ 개발 비용이 가장 많이 소요되는 단계 : 유지보수 단계
■ 절차지향 분석 기법 : 순차적, 하향식
■ 객체지향 분석 기법 : 동적 모델링, 상향식
■ 객체(Object) : 객체지향의 주요 구성 요소 중 데이터와 데이터를 처리하는 메소드를 묶어 놓은 하나의 소프트웨어 모듈
■ 클래스(Class) : 객체의 집합
■ 객체지향 설계원칙
(1) 단일 책임 원칙(SRP, Single Responsibility Principle) : 객체는 1개의 책임만
(2) 개방-폐쇄 원칙(OCP, Open Closed Principle) : 수정(변경)X, 추가(확장)O
(3) 리스코프 치환 원칙(LSP, Liskov Substitution Principle) : 자식 클래스는 부모 클래스에서 가능한 행위 수행
(4) 인터페이스 분리 원칙(ISP, Interface Segregation Principle)
(5) 의존 역전 원칙(DIP, Dependency Inversion Principle) : 추상성이 높은 클래스와 의존
■ 객체지향 분석 방법론
- Rumbaugh(럼바우) : 객/동/기
- Coad와 Yourdon 방법 : E-R다이어그램
- Boach 방법 : 미시적, 거시적
- Jacobson 방법 : Use case 강조
- Wirfs-Brock 방법 : 고객 명세서
■ 집단화: '부분-전체(Part-Whole)' 관계 또는 '부분(is-a-part-of)' 관계와 연관
■ UML 다이어그램
(1) 구조 (정적) 다이어그램 : 클래스, 객체, 컴포넌트, 배치, 복합체, 패키지
(2) 행위 (동적) 다이어그램 : 유스케이스, 시퀀스, 커뮤니케이션, 상태, 활동, 타이밍, 상호작용
■ 상태 다이어그램에서 객체 전이의 요인이 되는 요소 : event (이벤트)
■ 정형/비정형 명세법
(1) 정형 명세법
- 수학적 /모델링 기반 (ex. Z, LOTOS)
- 표현 명확, 간결 / 명세과 구현 일치 →but, 이해도 ↓
(2) 비정형 명세법
- 자연어(상태, 기능) 중심 (ex. ER모델링, 유스케이스 )
- 표현 다양, 간편 →but, 불충분한 명세가능성
■ FEP(Front End Processor) : 미리 처리하여 프로세스가 처리하는 시간을 줄여주는 하드웨어
■ Duplexing : 동일한 기능의 예비 시스템을 동시에 운용
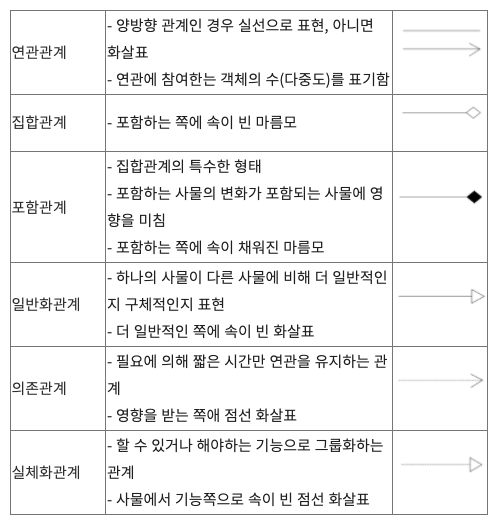
■ 연관 관계
■ CLI(Command Line Interface) : 정해진 명령 문자열을 입력
■ 모바일 제스처(Mobile Gesture) 에 속하는 것 (=모바일 기기에서 사용하는 행동)
: Press, Drag, Tap, Double Tap, Flick, Pan, Pinch 등
■ 와이어프레임(Wireframe) : 페이지의 뼈대 설계 (UI)
■ 유스케이스(Usecase) : 자연어 기반 기능 정의 (시나리오)
[ 2과목, 소프트웨어 개발 ]
■ Compile (컴파일) : 고급언어 프로그램을 기계어로 변환
■ Deployment : 배포
■ 단위 테스트(Unit Test) - 모듈,컴포넌트 단위
- 모듈 내부의 구조를 구체적으로 볼 수 있는 구조적 테스트를 주로 시행
- 구현 단계에서 각 모듈의 개발을 완료한 후, 개발자가 명세서의 내용대로 정확히 구현되었는지 테스트 함
- 테스트할 모듈을 (또는 테스트할 모듈이) 호출하는 모듈이 있음.
- 도구 : HttpUnit, CppUnit, JUnit
- 테스트 드라이버(Test Driver) : 테스트의 대상이 되는 하위 모듈을 호출하고, 파라미터를 전달하는 가상의 모듈로 상향식 테스트에서 필요한 것
■ 검증과 확인
- 검증 : 개발자, 개발 과정 테스트
- 확인 : 사용자, 결과 테스트
■ 코드 인스펙션 (Code Inspection)
- 프로그램을 수행시켜보는 것(동적) 대신에 읽어보고 눈으로 확인하는 방법(정적)으로 볼 수 있음 >> 정적 테스트(Static Testing) 기법
- 결함과 함께 코딩 표준, 준수 여부, 효율성 등의 다른 품질 이슈를 검사하기도 함.
- 코드 품질 향상 기법 중 하나
- 과정 : 계획 → 사전 교육 → 준비 → 인스펙션 회의 → 수정 → 후속조치
■ 마이그레이션 (Migration): 기존 SW 시스템을 새로운 기술 또는 하드웨어 환경에서 사용할 수 있도록 변환하는 작업
■ 스택에서 자료 삭제 시, Top이 0이면 Underflow 발생 (Top 은 스택포인터)
■ 클린 코드(Clean Code) 작성 원칙 : 중복성, 의존성, 가독성
■ RCS(Revision Control System) : 다른 방향으로 진행된 개발 결과를 합치거나 변경 내용을 추적할 수 있는 소프트웨어 버전 관리 도구 (동시에 소스 수정 방지)
■ 테스트 오라클 : 테스트 케이스 실행이 통과(참)되었는지 실패(거짓)하였는지 판단하는 기준 (ex. 샘플링)
- 참 오라클 : 모든 테스트 케이스의 입력 값에 기대하는 결과 제공
- 샘플링 오라클 : 특정 몇몇 테스트 케이스의 입력 값들에 대해서만 기대하는 결과 제공
- 휴리스틱 오라클 : 특정 테스트 케이스의 입력 값에 대해 기대하는 결과 제공, 나머지는 추정으로 처리
- 일관성 검사 오라클
■ 테스트 케이스 : 요구사항을 정확히 준수했는지 확인하기 위해 설계된 값으로 구성된 명세서
■ 테스트 시나리오 : 테스트 케이스들을 묶은 집합
■ 알고리즘 설계 기법
- Divide and Conquer(분할 정복): 큰 문제를 작은 문제로 분할하여 해결한 후, 다시 합쳐 전체 문제의 해답 도출 (ex. 병합 정렬, 퀵 정렬)
- Greedy Algorithm(탐욕 알고리즘): 매 단계에서 가장 최적이라고 판단되는 선택을 하여 전체 최적해를 구하려는 전략 (ex. 다익스트라 알고리즘, 크루스칼 알고리즘)
- Backtracking(백 트래킹): DFS를 기반으로 가능성이 없는 경로는 아예 탐색하지 않는 가지치기를 적용하는 최적화된 기법. (ex.N-Queen 문제, 순열 생성) >> (*깊이 우선 탐색(Depth First Search) 알고리즘: 모든 경우의 수를 탐색하는 알고리즘 )
■ 알고리즘
- STA (Spanning Tree Algorithm) : 브리지와 LAN 으로 구성된 통신망에서 루프(폐회로)를 형성하지 않고 연결
- DHA (Diffie-Hellman Algorithm) : 이산대수의 복잡성을 활용하여 사전 허락없이도 비밀 키 교환 가능
- DSA (Digitial Signature Algorithm) : 디지털 서명 기술을 제공하기 위해 이산대수의 복잡성을 활용 (공개키 암호화)
- Hash Algorithm : 메시지를 고정된 길이의 값이나 키로 변환 (EX. SHA(Secure Hash Algorithm), MD5 )
■ 인터페이스 구현 검증 도구
- STAF(Software Testing Automation Framework): 서비스 호출 및 컴포넌트 재사용 등 다양한 환경을 지원하는 테스트 프레임워크
- xUnit: NUnit, JUnit 등 다양한 언어를 지원하는 테스트 프레임워크
- FitNesse: 웹 기반 테스트케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
- NTAF(Naver Test Automation Framework) : Naver의 테스트 자동화 프레임워크 (FitNess + STAF)
- Watir (Web Application Testing in Ruby) : Ruby를 사용하는 애플리케이션 테스트 프레임워크
■ 소프트웨어 품질 목표
- 이식성(Portability): 하나 이상의 하드웨어 환경에서 운용되기 위해 쉽게 수정될 수 있는지 (설치성 포함)
- 효율성(Efficiency): 할당된 시간동안 한정된 자원을 얼마나 빨리 처리할 수 있는지
- 사용성(Usability): 사용자와 컴퓨터 사이에 발생하는 행위를 사용자가 정확히 이해하는지 (학습성, 접근성, 조작성)
- 신뢰성(Reliability) : 주어진 시간동안 주어진 기능을 오류 없이(기능 상의 장애 없이) 수행할 수 있는지
■ 스키마
- 외부스키마 : 사용자 뷰, 사용자나 개발자 관점
- 개념스키마 : 전체적인 논리적 구조 관점
- 내부스키마 : 물리적 저장장치 관점
■ 소스코드 품질분석 도구
(1) 정적: pmd, cppcheck, checkstyle, ccm, cobertura, SonarQube (소프트웨어적인 방법으로 코드분석)
(2) 동적: Avalanche, valMeter
■ EAI(Enterprise Application Integration) 구축 유형
- hub&spoke : 그룹 내의 담당 허브가 고장나면 전체에 영향
- messageBus : 그룹 담당
- Hybrid : hub&spoke && messageBus (중간에 미들웨어 있음)
■ 해싱 함수 종류 : 제곱법, 제산법, 숫자분석법, 중첩법, 기수 변환법, 무작위 방법
■ 개방주소법 : 해싱 충돌이 일어났을 때 빈 노드에 데이터 저장
■ 패키지 소프트웨어 국제 표준 : ISO/IEC 12119 (현재는 ISO/IEC 25010)
■ 알고리즘 시간복잡도
- O(1) : 비례X (항상 일정)
- O(log2^n) : 로그에 비례
- O(n) : 정비례 (선형)
- O(nlon2^n) : 로그*변수에 비례 (선형로그)
■ 정렬
- 선택 (Selection)
1회전: 최소값을 첫 번째 레코드에 놓기 → 2회전: 두번째 최소값을 두 번째 레코드에 놓기 → ...
- 퀵(Quick) : 분할과 정복, 피봇(pivot) 사용
■ 디지털 저작권 관리(DRM) : 크랙(해킹) 방지, 정책 관리, 암호화 기술 (방화벽 기술 사용X)
■ 화이트 박스 검사 : Nassi-Shneiderman 도표
■ 검색 효율이 가장 나쁜 트리 구조 : 이진 탐색트리 < AVL 트리 < 2-3 트리 < 레드-블랙 트리
■ 이진 검색 방법 : 중앙값을 기준으로 탐색 범위를 절반씩 줄여가며 찾는 방법
■ 코드 검사 수행 시 오류: 데이터 오류(DA), 논리 오류(LE, 서브루틴), 성능 오류(PF), 문서 오류(DC)
■ Chaining (체이닝) : 해시 함수가 서로 다른 키에 대해 같은 주소 값을 반환해서 충돌이 발생하면, 각 데이터를 해당 주소에 있는 링크드 리스트(Linked List)에 삽입하여 문제를 해결하는 기법
■ 연결 리스트 (Linked List)
- 노드들이 포인터로 연결되어 있어 찾아갈 때 검색 속도가 느림.
- 중간 노드 연결이 끊어지면 그 다음 노드 찾기 힘듬.
- 장점 : 노드의 삽입이나 삭제 쉬움.
■ 동치 분할 검사 (Equivalence Partitioning Test) : 입력 조건에 중점, 타당한 값과 그렇지 못한 값을 설정
■ 원인-효과 그래프 검사(Cause-Effect Graphing Testing) : 입력 조건과 출력 조건 간의 관계를 분석하여 테스트 케이스를 선정
■ 경계값 분석(Boundary Value Analysis) : 오류 발생 가능성이 높은 경계값을 중심으로 테스트 케이스를 선정 (동치 분할 기법 보완)
■ 인터페이스 표준 : 인터페이스 기능(내부), 데이터 인터페이스(외부)
■ 니블(Nibble) : 4개의 비트( Bit )가 모여 1개의 니블 구성 (8Bit = 1 Byte)
■ 워드(Word) : CPU가 처리할 수 있는 명령 단위
■ 비트(Bit) : 0 또는 1을 표시하는 2진수 한 자리
■ 체크인(Check-In) : 저장소에 새로운 버전의 파일로 갱신
■ 정점 n개인 방향 그래프의 최대 간선 수 구하기 : n(n-1)
[ 3과목, 데이터베이스 구축 ]
■ 기본키(Primary Key) 특징: NOT NULL, 유일성, 외래키로 참조될 수 있음, 릴레이션에서 튜플 구별 가능(고유성)
■ 슈퍼키: 모든 튜플에 대해 유일성 O >> NOT NULL (한 개 이상의 속성들의 집합으로 구성되어 있음)
■ 후보키(Candidate Key) : 유일성O, 최소성 O (개체를 고유하게 식별 가능)
■ 대체키 : 후보키 중 기본키를 제외한 나머지
■ 데이터 모델의 구성 요소 : Struture(구조), Constraint(제약조건), Operation(동작, 실제 값들을 처리하는 작업)
■ SQL
- DDL : Create, Alter, Drop ★암기 Tip★ 캐드(CAD)
- DML : Select, Insert, Update, Delete
- DCL : Grant, Revoke, Commit, Rollback
■ Drop과 Delete
- Drop : 테이블 (인덱스, 뷰) 삭제
- Delete : 테이블 내 레코드(=튜플) 삭제
■ Modify : 테이블 내 컬럼의 데이터 유형, 기본값, Not null, 제약조건 등을 수정
■ Alter : 테이블 내 컬럼을 수정
■ 릴레이션(relation, 관계) 특징
- 각 행 : 튜플(Tuple) / 각 열 : 속성(Attribute)
- 스키마 : 한 개의 릴레이션의 논리적인 구조를 정의 (이름과 속성들의 집합을 의미)
■ 뷰(View)
- 인덱스 X (가상 테이블이라 데이터가 없어서)
- 삽입, 갱신, 삭제 연산 시 제약 O
■ 무결성 제약조건
(1) 개체 무결성 : 기본키는 NOT NULL, NOT 중복
(2) 참조 무결성 : 외래키는 부모 기본키와 동일
(3) 도메인 무결성 : 각 속성의 도메인에 정해진 값이어야 함
(4) 고유 무결성 : 고유한 값을 가져야 함
(5) NULL 무결성 : NOT NULL 인 값 존재가 있을 수 있음.
(6) 키 무결성 : 1개 이상 키 존재
■ 분산 데이터베이스 시스템(Distributed Databases System)
- 단점: 데이터베이스의 설계가 비교적 어렵고, 개발 비용과 처리 비용이 증가
- 위치 투명성(Location), 중복 투명성(Replication), 병행 투명성(Concurrency, 장애 투명성(Failure)을 목표로 함
- 시스템의 주요 구성 요소 : 분산 처리기 , p2p 시스템 (단일 데이터 베이스는 논리적 데이터 베이스에 적합)
■ 데이터베이스의 병행제어의 목적 : 시스템 활용도 최대화, 사용자에 대한 응답시간 최소화, 데이터베이스 일관성 유지
■ 소프트웨어의 설계 단계: 요구사항 분석 → 개념적(Conceptual) 설계 → 논리적(Logical) → 물리적(Physical) → 구현
(1) 개념적 설계 단계 : E-R Diagram >> 엔터티, 관계, 속성 정의
(2) 논리적 설계 단계: 정규화, 트랜잭션 인터페이스 설계, 스키마 평가 및 정제
(3) 물리적 설계 단계: DBMS 관점에서 저장 레코드 관련 작업 수행, 클러스터링, 인덱스
■ 정규화 (normalization) → 목적 : 중복 배제
제 1 정규형(1NF) : 모든 도메인이 원자값만으로 되어 있음.
제 2 정규형(2NF) : 부분 함수 종속 제거 (기존키의 일부가 아닌 다른 속성에 종속된 속성들을 제거하며 전체 함수 종속만 남김)
=>즉, 완전 함수적 종속을 만족해야 함.
제 3 정규형(3NF) : 이행적 함수 종속 제거(ex. A->B 이고 B->C 일때, A->C를 제거하여 B가 C를 결정하는 관계 명확하게)
보이스-코드 정규형(BCNF) : 모든 결정자가 후보키
제 4 정규형(4NF) : 다치 종속 제거
제 5 정규형(5NF) : 조인 종속 제거
■ Partially Committed : 트랜젝션의 마지막 연산이 실행된 직후의 상태로, 모든 연산의 처리는 끝났지만 트랜잭션이 수행한 최종 결과를 데이터베이스에 반영하지 않은 상태
■ Recovery (회복) : 손상된 DB를 손상되기 이전의 정상적인 상태로 복구시키는 작업
■ 철회 (Rollback): : 트랜잭션 수행에 실패하여 Rollback 연산까지 수행한 상태
■ 부분 완료 (Partial Commit) : 모든 트랜잭션 실행하였으나, Commit 전
■ Commit 과 Rollback 명령어에 의해 보장받는 트랜잭션의 특징 : 원자성
■ Anomaly(이상) : 데이터 중복으로 인하여 관계 연산 처리 시, 예기치 못한 곤란한 현상이 발생하는 것 (삽입이상, 갱신이상, 삭제이상)
■ McCade의 cyclomatic 수 구하기 : 면의 수(사방이 막힌 공간의 수) +1
■ 트리의 차수(degree) 구하기 : 가장 자식노드가 많은 노드의 차수
■ 테스트 단계 (V형 모델)
요구사항 분석 -----------------(인수 테스트) : 알파(개발자+사용자 같이), 베타(사용자끼리)
기능명세 분석 ----------(시스템 테스트) : 기능, 비기능
설계 ----------------(통합 테스트) : 상향(가장 하위부터 , 드라이버), 하향(가장 메인부터, 스텁) , 빅뱅(한번에 다), 백본(상+하, 비용 高)
개발 ---------- (단위 테스트) :정적, 동적
- 단위 : 모듈, 컴포넌트 단위로 테스트
- 통합 : 모듈 결합하여 테스트
- 시스템 : 완성품이 해당 컴퓨터에서 수행되는지 테스트
- 인수 : 완성품이 사용자 요구사항 충족하는지 테스트
■ 데이터웨어하우스의 OLAP(On-Line Analytical Processing) 연산
: roll-up(상위 데이터 집계), drill-down(하위 데이터 집계) ,dicing(다차원 데이터를 잘라서 특정 부분 집합을 분석)
■ 트랜잭션의 특징 (ACID 속성)
- Durability(영속성): 트랜잭션이 성공적으로 완료(Commit)된 후에는 시스템 장애가 발생하더라도 결과가 영구적으로 유지됨.
- Insolation(독립성): 하나의 트랜잭션이 실행되는 동안 다른 트랜잭션이 개입할 수 없으며, 중간 연산이 다른 트랜잭션에 영향을 미치지 않음.
- Consistency(일관성): 트랜잭션 실행 전과 후에 데이터의 무결성과 제약 조건이 유지되어야 함.
- Atomicity(원자성): 트랜잭션의 연산은 모두 수행되거나(Commit), 전혀 수행되지 않도록(Rollback) 보장되어야 함. (한꺼번에)
■ Restrict(제한): 삭제할 대상이 다른 곳에서 참조하고 있으면, 삭제가 허용되지 않고 해당 트랜잭션이 취소됨.
■ 시스템 카탈로그 (System Catalog)
- 정의: DBMS가 스스로 생성하고 유지 관리하는 특별한 테이블의 집합
- 카탈로그에 저장된 정보를 메타 데이터라고 함.
- 정보 유지 관리: 데이터베이스의 테이블, 컬럼, 인덱스 등 데이터 객체에 대한 정의와 명세 정보를 유지관리.
- 조회 권한: 일반 사용자는 SQL을 통해 조회(검색)할 수 있지만, 갱신은 허용되지 않음.
■ 관계대수 및 관계해석 >> 둘은 관계 데이터베이스에서 동등한 기능을 제공하지만 접근 방식이 다름.
(1) 관계대수(Relational Algebra)
- 정의: 릴레이션(테이블)을 처리하기 위한 연산의 집합 (피연산자가 릴레이션이고 결과도 릴레이션)
- 특성: 절차적(Procedural) 특성, 어떻게 정보를 유도할 것인지를 정의
- 기능: 관계를 연산하는 방법과 순서를 명시적으로 정의
- 연산 : Select, Project, Join, Division
- EX. 선택(Selection), 투영(Projection), 합집합(Union), 차집합(Difference), 교차(Intersection) 등
(2) 관계해석(Relational Calculus)
- 정의: 수학의 프레디킷 해석에 기반을 두고, 원하는 정보가 무엇인지를 정의 하는 방식
- 특성: 비절차적(Non-procedural) 특성 , 결과적으로 얻고자 하는 정보를 정의
- 기능: 원하는 정보만 정의하고, 그 구현은 DBMS에 맡김
- EX. 튜플 해석, 도메인 해석 등
■ 차수(Degree) 및 카디널리티(Cardinality)
- 차수(Degree): 속성의 수
- 카디널리티(Cardinality): 튜플의 수
■ 뷰(VIEW) : 가상 테이블 >> CUD 연산에 제약이 있음
- 뷰 수정 방법: (1)삭제 후 재생성(Drop, Create) , (2) 재정의(Create Or Replace 뷰이름)
■ SQL문
- 테이블 관련 수정 : UPDATE [테이블명] SET [열]
- 테이블 권한 부여 : GRANT UPDATE (특정컬럼 있으면) ON [테이블명] TO [사용자명]
■ 데이터베이스 관리 시스템(DBMS) 장애 발생 시 회복 기법
- 즉각 갱신 기법 (Immediate Update) : 즉시 데이터베이스 로그(log)를 이용해 복구
- 대수적 코딩 방법 (Algorithmic Coding) : 수학적 모델로 표현
- 타임 스탬프 기법 (Timestamping) : 트랜잭션의 순서를 정의
- 폴딩 기법 (Folding Technique) : 여러 트랜잭션을 하나의 단위로 묶어 관리
■ 인접 행렬(Adjancency Matrix)
- 방향 간선이 없는 것 : 0
- 방향 간선이 있는 것 : 1
■ Division 연산 수행 : 겹치는 두 릴레이션 중, 작은 릴레이션을 제외하고 남은 큰 릴레이션의 데이터
■ 수평 분할 기법 : 범위 분할, 목록 분할, 해시 분할, 조합 분할, 라운드로빈 분할 (예측분할은 X)
■ 참조 테이블 옵션
- CASCADE
- SET NULL : 자식 null 됨.
- SET DEFAULT : 자식 기본값 됨.
- NO ACTION : 자식 삭제 안되도록 지정.
■ 카티션 프로덕트(Cartesian Product, 교차곱) : 차수(속성 수+), 카디널리티(튜플 수*) 구하기
■ 2단계 로킹 규약(Two-Phase Locking, 2PL)
- Lock과 Unlock이 동시에 수행X
- 확장 단계(Growing Phase): Lock 수행가능, Unlock은 수행불가능
- 축소 단계(Shrinking Phase): Unlock은 수행 가능하지만 새로운 Lock을 획득X
- 교착 상태(Deadlock)가 발생할 수 있음.
■ 두 릴레이션 중 카디널리티가 작은 릴레이션의 카디널리티보다 크지 않은 연산자 : 교집합
ex) A의 튜플 수 : 5개 / B의 튜플 수:3개 / 공통 튜플 수 : 2개
합집합 : 6개 / 차집합 : 5개 / 교집합 : 2개 => 가장 작은 튜플 수(B)와 같거나 작은 !!
■ 차집합(Except, Difference) = 첫 번째 릴레이션의 튜플 수
■ 교집합(Intersection) = 두 릴레이션의 공통 튜플 수
■ 트리거(Trigger) : 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL
[ 4과목, 프로그래밍 언어 활용 ]
■ 스크립트 언어 : PHP, Python, Basic(절차지향)
■ 개발 환경 구성을 위한 빌드(Build) 도구 : Gradle(Java 기반), Maven (XML기반) , Ant ( XML기반)
■ SW개발에서 모듈이 되기 위한 주요 특징
- 독립적인 컴파일 가능
- 유일한 이름 가져야 함
- 다른 것들과 구별될 수 있는 독립적인 기능을 가진 단위(Unit)
- 모듈 간의 캡슐화 => 다른 모듈에서의 접근이 가능해도 됨
■ 클래스별 IP 주소 범위 정리
A : 1 ~ 126 / 서브넷 마스크 : 255.0.0.0 (대 규모)
B : 128 ~ 191 / 서브넷 마스크 : 255.255.0.0 (중간 규모)
C : 192 ~ 223 / 서브넷 마스크 : 255.255.255.0 (소 규모)
D : 224 ~ 239 (멀티캐스트)
F : 240 ~ 255 (연구용)
■ HTTP 포트 번호 : 80
■ 8 bit = 1 byte
■ 내용 결합도(Content Coupling): 한 모듈이 다른 모듈의 내부 기능 및 그 내부 자료를 참조하는 경우
■ 공통 결합도 : 두 모듈이 동일한 전역 데이터에 접근하는 경우
■ 스탬프 결합도 : 두 모듈이 매개변수로 자료를 전달할 때, 자료 구조 형태로 전달되는 경우\
■ 결합도 (Coupling) : 외부
내용(content) > 공통(common) > 외부(external) > 제어(control) > 스템프(stamp) > 자료(data)
★암기 Tip★ (내)게 (공)(부)하라고 강요하지 말아요
(제)가 (스)트레스 받(자)나요
■ 응집도 (Cohesion) : 내부
기능(functional) > 순차(sequential) > 교환(communicational) > 절차(procedural) > 시간(temporal) > 논리(logical) > 우연(coincidental)
★암기 Tip★ (기)(차)표 (교환)할래? (절차)(시간) 곧 올것 같아. (논)(현) 역이요
■ IP 프로토콜 주요 특징
- 패킷을 분할, 병합하는 기능을 수행
- 비연결형 서비스 제공
- Best Effot 원칙에 따른 전송 기능을 제공
- 데이터 체크섬(Data Checksum) 기능 제공X (헤더 체크섬만 제공)
- 헤더 길이 : 32비트 워드 단위
- 패킷 길이 (헤더 길이 제외): 최대 크기는 2¹⁶ - 1
- Version Number: IP 프로토콜의 버전 (IPv4: 4, IPv6: 6 등)
■ UNIX 운영체제 특징
- 트리 구조 파일 시스템
- 이식성 高, 장치 간 호환성 高
- 멀티 유저(Multi-User) 및 멀티 태스킹 (Multi-Tasking) 지원
■ 커널: 쉘 프로그램 실행을 위해 프로세스와 메모리를 관리
■ UNIX 시스템의 쉘(shell) 주요 기능
- 사용자 명령을 해석하여 커널로 전달
- 초기화 파일을 이용해 사용자 환경을 설정하는 기능 제공
■ 리눅스 명령어
- uname : 커널의 이름, 버전 등 시스템 정보 확인
- ls: 현재 디텍토리의 파일 목록 확인
- chmod: 파일 권한 변경
- cat : 파일 내용 출력
- cp : 파일 복사
- rm : 파일 삭제
- fork: 새로운 프로세스 생성
- type: 프로그램 종류 확인
- mkdir: 폴더 생성
- ftp (File Transfer Protocol): 파일을 다른 시스템으로 전송
- nmap : 네트워크 스캐닝 도구 (포트 스캔하여 정보 수집)
- printenv , env , setenv : 환경 변수 출력 (export)
- echo $변수명 : 변수 출력
■ 유닉스 명령어
- find : 파일 찾기
- fork : 새로운 프로세스 생성
- exec : 새로운 프로세스 실행
- wait : 부모 프로세스 임시 중단
■ CHKDSK : Windows에서 디스크의 상태를 확인하는 명령어
■ FORMAT : 디스크 표면을 트랙과 섹터로 나누어 초기화
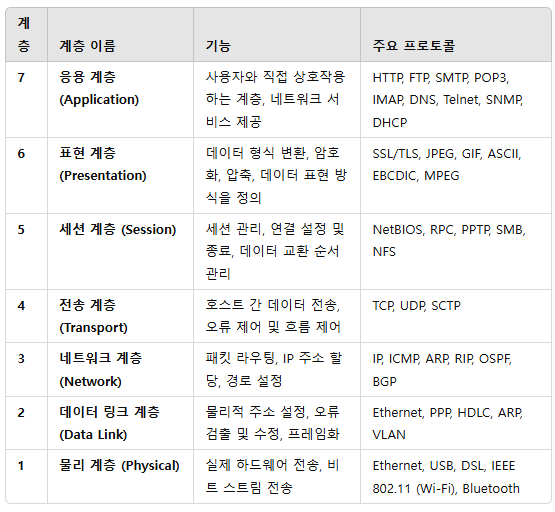
■ OSI 계층
(7) 응용 계층 (Application Layer): 사용자와 네트워크 간의 직접적인 상호작용(실제 접속)을 담당 (ex. 웹 브라우저, 이메일)
-프로토콜 : HTTP, FTP, SMTP, IMAP, DNS, SSH
(6) 표현 계층 (Presentation Layer): 데이터 포맷을 정의하고 변환, 암호화 및 압축 수행
-프로토콜 : TLS, SSL, JPEG, MPEG, GIF
(5) 세션 계층 (Session Layer): 응용 프로그램 간 연결을 설정하고 유지하며, 종료 (토큰 사용)
-프로토콜 : NetBIOS, RPC, PPTP
(4) 전송 계층 (Transport Layer): 단말기 사이(종단 간, End-to-End)의 오류를 처리, 신뢰성 있는 데이터 전송(D)보장 (세그먼트)
-프로토콜 : TCP, UDP, SCTP, RTP
(3) 네트워크 계층 (Network Layer): 네트워크 관리 및 데이터의 경로를 설정하고, 패킷 전송(P)을 담당, IP 주소 사용
-프로토콜 : IP, ICMP, IPSec, ARP, RIP, OSPF
(2) 데이터 링크 계층 (Data Link Layer): 링크의 설정과 유지 및 종료 , 동기화, 오류제어, 프레임(F) 전송(MAC 주소 기반)
-프로토콜 : Ethernet, PPP, SLIP, HDLC, ARP, LLC
(1) 물리 계층 (Physical Layer): 전기적, 기계적 방식으로 비트(bit)단위의 데이터 전송을 담당
-프로토콜 : Coax, Fider, Wireless, Bluetooth
■ OSI 7 계층에서 사용되는 네트워크 장비
-리피터(Repeater): 전송되는 신호가 원래의 신호 형태로 재생하여 다시 전송하는 역할 (물리 계층)
-브리지(Bridge): LAN과 LAN 을 연결하거나 LAN 안에서의 컴퓨터 그룹을 연결 (데이터 링크 계층 중 MAC 계층)
-스위치 (Switch): LAN과 LAN을 연결하여 훨씬 더 큰 LAN을 만드는 장치 (OSI 7계층의 2계층, 데이터 링크 계층)
-라우터 (Router): LAN과 LAN의 연결 기능에 데이터 전송의 최적 경로를 선택할 수 있는 기능이 추가된 것 (네트워크 계층)
■ RPC (Remote Procedure Call) : 원격 프로시저를 로컬 프로시저처럼 호출
■ UDP(User Daragram Protocol) 프로토콜 특징
-비연결형 서비스 제공
-단순한 헤더 구조로 오버헤드가 적음
-TCP와 같이 전송(트랜스포트) 계층에 존재
- 흐름제어나 순서제어가 없어 전송속도가 빠름
- 69 포트 : TFTP
■ TCP 프로토콜 특징
-인터넷 상에서 데이터를 안정적으로 전송하기 위한 프로토콜
-패킷 전송 제어( 흐름 제어, Flow Control)+오류 검출 및 복구
-전이 중(Full Duplex) 방식의 양방향 가상회선을 제공 (투명성 보장됨)
-체크섬(오류체크) 발생
- 23 포트 : Telnet
■ UTP 53 포트 : DNS
■ UTP 111 포트 : RFC
■ 논리 (IP주소) → 물리 (MAX주소) : ARP
■ C언어 -문자열 함수
- strlen(s) : s의 길이
- strcmp(s1,s2) : s1>s2 면 양수, s1<s2 면 음수, s1=s2 면 0
- strrev(s) : s를 거꾸로 변환
- strcpy(s1,s2) : s2를 s1로 복사
■ C언어 라이브러리
- stdlib.h : 자료형 변환
- string.h : 문자열 처리
- stdio.h : 표준 입출력
- match.h : 수학 함수
- 헤더 파일 호출 : #include
■ Best Fit 전략 : 여유공간이 남는 가장 가까운 기억공간 선택
- ex) 17KB 프로그램 적재 시, 20KB 선택하여 남는 여유 공간(=내부단편화)은 3KB
■ Worst Fit 전략 : 가장 낭비가 심한 영역 선택
■ First Fit 전략 : 가장 빠른 영역 선택
■ 상호배제를 위한 알고리즘 기법
-Dekker Algorithm(데카의 알고리즘): flag와 turn 변수를 사용하여 상호배제를 보장하는 최초의 소프트웨어 기반 알고리즘.
-Lamport Algorithm(램퍼드 알고리즘): 프로세스 간 우선순위를 부여하여 상호배제를 보장하는 알고리즘.
-Peterson Algorithm(피터슨 알고리즘): 데카의 알고리즘과 유사하지만, 상대방에게 진입 기회를 양보하고, 더 간단한 구현.
-Semaphore(세마포어): 여러 프로세스 또는 스레드가 공유 자원에 동시 접근하지 못하도록 제어하는 동기화 기법.
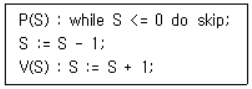
■ PHP 연산자: @(변수나 함수 이름 앞에), <>(비교), ===(일치)
■ HRN 방식 계산방법
우선순위 계산식 = (대시 시간 + 서비스 시간) / 서비스 시간
■ 운영체제의 운용 기법
- Time Sharing Processing System(시분할 처리): 일정 시간 단위로 다음 사용자에게 전환
- Batch Processing System(일괄 처리): 한꺼번에 처리
- Real Time Processing System(실시간 처리 ): 즉시 처리
- Multi Programming System(다중 프로그래밍): 여러 프로그램 동시 처리
■ Python 데이터 타입
- 리스트(list) : 순서 O, 변경 O
- 튜플(tuple) : 순서 O, 변경 X
- 딕셔너리(dict): 순서 X, 키-값 쌍으로 저장, 여러 데이터 타입을 값으로 가질 수 있음.
- 복소수(complex): 실수 부분과 허수 부분을 포함
■ 버퍼 오버플로 : 메모리 다룰 때 오류가 발생하여 잘못된 동작을 하는 프로그램 취약점
■ 충돌 관련 기법
- CSMA/CA(Avoidance) : 충돌 회피
- CSMA/CD(Detection) : 충돌 감지 <= IEEE 802.3 LAN 에서 사용되는 전송 매체 접속 제어(MAC)방식
- Collision Domain : 충돌 도메인
■ 교착상태가 발생하는 조건
- 상호 배제 (Mutual exclusion)
- 점유와 대기 (Hold and wait)
- 비선점 (Non-preemption)
- 환형 대기 (Circular wait)
■ 제어 프로그램 : 감시 프로그램, 작업 제어 프로그램, 데이터 관리 프로그램
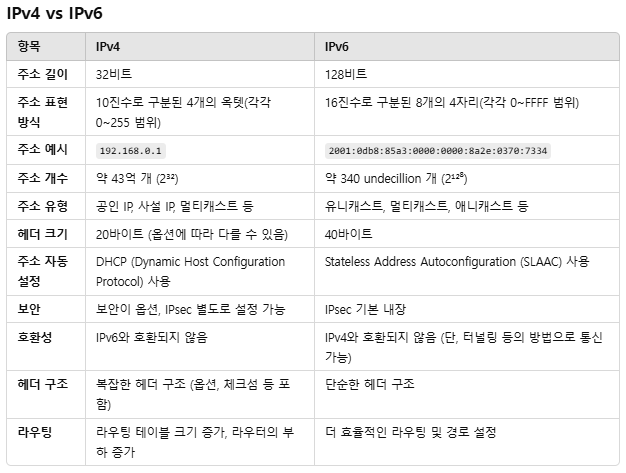
■ IPv4 와 IPv6
- 주소 전환 기술 : 듀얼 스택(Dual Stack), 터널링(Tunneling), 헤더 변환(Header Translation)
★암기 Tip★ 듀링헤 (규림해)
(1) IPv4
- 헤더 구조 : 20~60 바이트, 고정 크기가 아님 (복잡)
- 주소 길이 : 32 비트
- 주소 표현: 10진수 (점으로 구분, 4옥텟) 예: 192.168.1.1
- 주소 유형 : 유니캐스트, 멀티캐스크, 브로드캐스트
- 라우팅 효율성: 라우팅 테이블이 큼 (비효율적)
(2) IPv6
- 헤더 구조 : 40 바이트, 고정 크기 (단순화됨)
- 주소 길이 : 128 비트
- 주소 표현: 16진수 (콜론으로 구분, 8그룹) 예: 2001:0db8:85a3::8a2e:0370:7334
- 주소 유형 : 유니캐스트, 멀티캐스크, 애니캐스트
- 보안: IPsec 기본 내장
- 라우팅 효율성: 라우팅 테이블 크기 감소 (더 효율적)
■ 서브넷 마스크(Subnet Mask) 구하기
(1) 이진수로 만들기 : 마지막 /@@ 에서 @@ 비트 자리까지 1로 채우고 뒤에는 0으로 채우기
( 8 ) ( 8 ) ( 8 ) ( 8 ) 으로 구성되어 있음
(2) 10진수로 변환 (각 자리수의 2의 거듭제곱의 합)
1111 1111 = 255
1110 0000 = 224
1100 0000 = 192
(예.) CIDR 표기로 203.241.132.81/27 과 같이 사용되었다면, 해당 주소의 서브넷 마스크는?
/27 => 27을 이진수로 만들기
( 8 ) ( 8 ) ( 8 ) ( 8 ) 으로 구성되어 있음
>> 세번째까지 1이라고 가정하고 다 더하면, 24
>>> 마지막 8비트 짜리를 27번째자리까찌 1을 채움 >>>> 1110 0000
10진수로 변환 => 224
■ broadcast 주소 : 해당 IP 주소 내 가장 마지막 주소
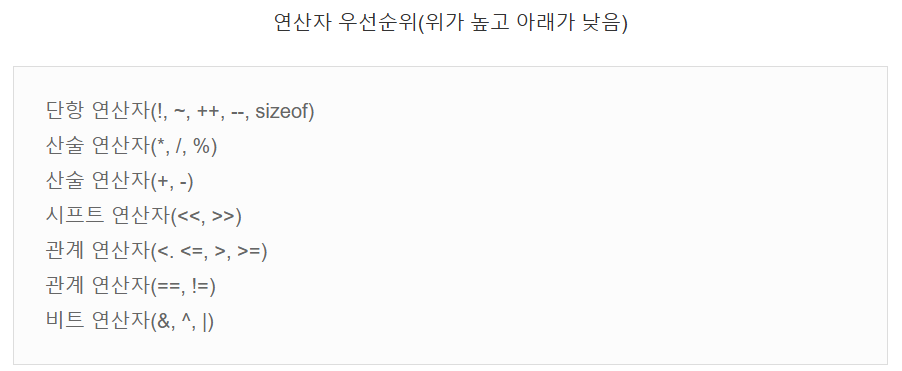
■ 비트 연산 방법
- r << n → r * 2^n (왼쪽 시프트, 2의 n승만큼 곱하기)
- r >> n → r / 2^n (오른쪽 시프트, 2의 n승만큼 나누기)
■ C언어 에서 mallco() 함수 : 입력한 Byte 만큼 메모리 할당
■ C언어의 비트 논리 연산자
& : 비트 AND (둘 다 1이면 1, 아니면 0)
^ : 비트 XOR (둘이 다르면 1, 같으면 0)
~ : 비트 NOT (비트를 반전)
■ 비트 연산 (a | b : 최댓값 ), 논리 연산 (a || b : 둘다 0이 아니면 1)
■ 논리 OR (||) 연산자
- 둘 중 하나라도 true면 true 반환
- 둘 다 false일 때만 false 반환
■ 논리 AND (&&) 연산자 (깔끔한 놈)
- 둘 다 true일 때만 true 반환
- 하나라도 false이면 false 반환
■ !a && !b = !(a||b)
■ 자동 반복 요청 방식(ARQ)
- Stop-and-wait ARQ
- Go-back-N ARO
- Selective-Repeat ARQ (선택적 전송)
■ ArithmeticException : 산술 연산에 대한 예외 객체
■ 페이지 교체(Page Replacement) 알고리즘 : FIFO, OPT(Optimal), LRU(Least Recently Used)
, LFU (Least Frequently Used) , NUR (Not Used Recently) , SCR (Second Chance) 등
■ Locality (구역성) : 일정 부분만을 집중적으로 참조한는 것
■ 시간 구역성(Tempral Locality) : 최근에 참조된 데이터가 가까운 시간 안에 다시 참조될 가능성
ex) 스택, 순환문, 부프로그램
■ 공간 구역성(Spatial Locality) : 인접한 데이터가 순차적으로 참조될 가능성 (ex) 배열 순회, 배열 순례
■ 페이징 크기 ↓ = 내부 단편화 ↓ = 페이지 개수 ↑ = 맵 테이블 크기 ↑ = 입출력 시간 ↑
■ 페이지 오류율 ↑ = 스래싱(=페이지 교체) ↑
■ Working Set (워킹 셋) : 페이지들의 집합 (계산법 : 중복제거)
■ 다중 프로그래밍 정도는 어느 수준이상 높아지면 스래싱의 발생 빈도를 높여서 안좋음!
■ 버스형 : 한 개의 통신 회선에 여러 대의 단말장치가 연결되어 있는 형태를 가진 네트워크 토폴로지
■ 스래싱(Thrashing) : 페이지 교체에 소요되는 시간이 더 많아지는 현상
■ 프로세스
- 비동기적 행위를 일으키는 주체 (디스패치 가능)
- PCB를 가지며, PCB는 프로세스의 현재상태, 고유식별자를 가지고 있음.
■ 사용자 수준 스레드 (User-Level Thread, ULT) : 운영체제(커널) 관여 없이 사용자가 직접 관리하는 스레드 >> 오버헤드 줄어듬
( 한 개의 스레드가 블로킹되면, 전체 프로세스가 블로킹됨)
■ 커널 수준 스레드 (Kernel-Level Thread, KLT) : 운영체제(커널)가 직접 관리하는 스레드
( 스레드가 블로킹되더라도 다른 스레드가 실행될 수 있음 (멀티스레딩 가능) )
■ 스케줄링
(1) 선점 : 강제 빼앗기 O => 시분할 시스템에 유리
ex. RR(Round Robin), SRT,선점 우선순위, 다단계 큐, 다단계 피드백 큐 등
(2) 비선점 : 강제 빼앗기 X => 일괄 처리 시스템에 유리
ex. FCFS, SJF, 우선순위, HRN, 기한부 등
■ SSTF(Shortest Seek Time First) 스케줄링 : 현재 헤드위치와 이동 거리가 짧은 것들부터
[ 5과목, 정보시스템 구축 관리 ]
■ 암호화 방식
(1) 양방향
(1-1) 개인키 암호화 (=대칭, 비밀키) : 키 1개 / 속도 빠름 / 키의 수 多
(1-1-1) Block(블록) 방식 : 데이터 블록 단위로 암호화
- ex) DES, AES, ARIA(2004), IDEA, SEED
(1-1-1) Stream(스트림) 방식 : 비트/바이트/워드 단위로 순차적으로 암호화
- ex) RC4, LFSR
(1-2) 공개키 암호화 (=비대칭) : 키 2개(공개키, 비밀키) / 키의 수 少 (공식: 2*인원 수)
- ex) RSA
(2) 단방향 - 해시 암호화
- ex) SHA 시리즈, SNEFRU, MD5, RIPEMD-160, N-NASH
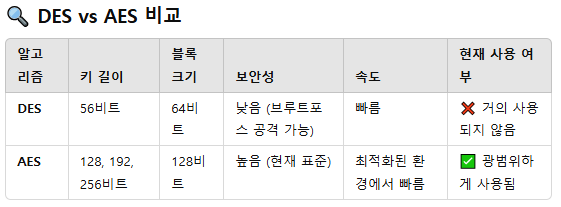
■ DES와 AES
(1) DES(Data Encryption Standard, 블록 크기 64 비트, 키 길이 56 비트 )
- 키 길이가 짧아 브루트포스 공격(무차별 대입 공격)에 취약 => 강력한 암호화 방식(AES)로 대체
(2) AES(Advanced Encryption Standard, 128비트)
- 보안성 高 (현재 표준)
- 2001년에 미국 표준 기술 연구소에서 발표함
■ 테일러링(Tailoring)
- 프로젝트에 최적화된 개발 방법론을 적용하기 위해 절차, 산출물 등을 적절히 변경하는 활동
- 변화에 유연한 대응
- 관리 측면에서의 목적: 사전 위험 식별 및 제거, 최단기간 내 프로젝트 진행
- 기술적 측면에서의 목적: 프로젝트 특성에 맞는 기술 도입
■ Honeypot
- 비정상적인 접근의 탐지를 위해 의도적으로 설치해 둔 시스템
- 목적: 크래커 추적 및 공격기법의 정보 수집 (침입자를 속여 실제 공격당하는 것처럼 보여줌)
- 특징: 쉽게 공격자에게 노출되고 취약해 보이기 (공격자가 이를 타겟으로 삼게 만듬)
■ Windows 파일 시스템
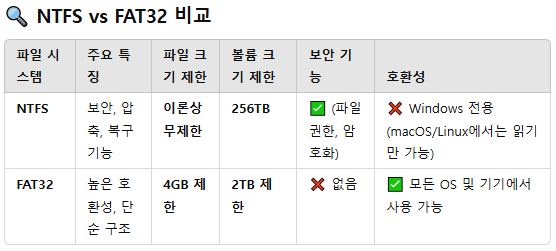
- NTFS(New Technology File System): 자동 압축 및 안정성 高 => 대용량에 최적화
- FAT(File Allocation Table): 단순, 호환성 좋음 => 파일 크기(4GB) 및 안정성에 한계
■ RSA (Rivest-Shamir-Adleman) : 큰 숫자를 소인수 분해하는 것이 어렵다는 수학적 문제에 기반한 공개키 암호화 알고리즘( 1978년 MIT )
■ Rabin : 소인수 분해의 어려움에 안정성 기반 암호화 알고리즘 ( RSA 의 대체)
■ ECC(Elliptic Curve Cryptograthy) : 이산 대수 문제를 타원곡선으로 옮긴 암호화 알고리즘
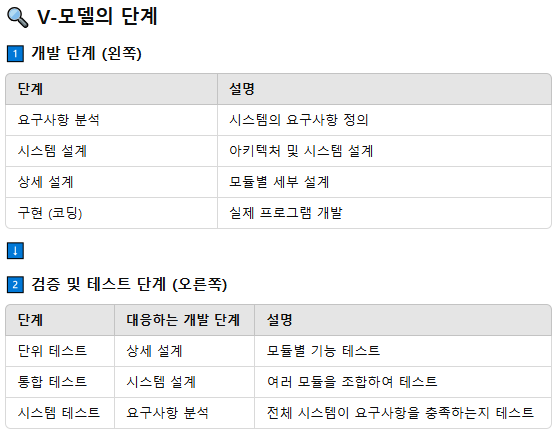
■ V모델 (SW 생명주기 모델, SDLC, Software Development Life Cycle)
- Perry에 의해 제안
- 폭포수 모델의 확장형 : 개발 및 검증 작업 관계를 명확히 (폭포수는 개발이 완전히 끝난 후에 검증 진행)
- 개발과 검증이 병렬 구조로 진행됨: 왼쪽(개발 단계)와 오른쪽(테스트 단계)가 V자로 구성됨
- 신뢰성 높은 시스템 개발에 적합 : 세부적인 테스트 과정으로 구성됨
- 요구 분석 및 설계 과정 없이 바로 V-형태의 검증 단계가 진행됨 => 통합 테스트 중심의 구조
■ 공격 기법
(1) Ping Of Dearth (죽음의 핑): 허용 범위 이상의 ICMP 패킷 전송하여 마비시킴 (과부화로 오버플로우 일으킴)
(2) Session Hijacking (세션 하이재킹): 클라이언트의 세션 정보(쿠키, 세션ID) 가로채기
>> 탐지 방법: 비동기화 상태 탐지, ACK Storm 탐지, 패킷의 유실과 재전송 증가 탐지, 예상치 못한 접속의 리셋 탐지 등
(3) Piggyback Attack (피기백 공격): 권한 있는 사용자가 이미 열어둔 통신 경로로 몰래 접근 (신뢰를 악용)
(4) XSS (크로스사이트 스크립팅, Cross Site Scripting): 웹에 악의적인 스크립트 삽입
(5) Land 공격 : 패킷 전송 시, 출발지 IP주소와 목적지 IP주소 값을 똑같이 만들어서 공격 대상에게 보내는 공격 (무한루프)
(6) SYN Flooding : 가짜 클라이언트들이 서버의 한정된 접속 공간을 차지하도록 속여 실제 사용자들의 접속을 방해 (Half-Open 상태)
(7) Smurf 공격 : ICMP Echo Request 패킷을 다수의 시스템에 전송해 공격 대상의 IP를 출발지 주소로 위조 (브로드캐스트를 활용) > 여러 시스템이 공격 대상에게 Echo Reply를 보내게 되어 트래픽 폭주를 일으킴. (브로드캐스트와 ICMP를 이용한 공격 기법 )
(8) Ransomware (랜섬웨어): 암호화한 후, 복호화를 위해 금전적인 요구를 하는 악성 소프트웨어.
(9) Phishing (피싱): 허위 웹 사이트로 개인 정보 탈취
(10) Pharming(파밍) : 도메인 탈취 및 DNS 이름 속여서 진짜 사이트로 오인하도록 유도
(11) Switch Jamming(스위치 재밍) : 위조된 매체 접근 제어(MAC) 주소로 더미 허브(Dummy Hub)처럼 작동하게 하는 공격
(12) Tiny Fragment : 패킷을 작게 만들어서 분석 못하도록 하는 공격
■ Worm(웜) : 자기 복제 등 스스로를 증식하는 악성코드
■ tripwire : 크래커가 침입하여 백도어를 만들어 놓거나, 설정 파일을 변경했을 때 분석하는 도구
■ 블루트스 공격
- 블루버그(BlueBug) : 블루투스 장비 사이의 취약한 연결을 공격
- 블루스나프(BlueSnarf) : 인증없이 정보 교환하는 OPP 사용하여 정보 열람
- 블루프린팅(BluePrinting) : 블루투스 공격 장치의 검색 활동
- 블루재킹(BlueJacking) : 블루투스를 이용해 스팸처럼 명함을 익명으로 퍼뜨리는 것
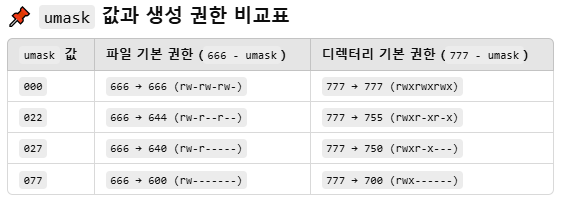
■ 리눅스 파일 권한과 umask 값 계산
- 생성 권한 = ( 파일 기본 권한 : 666 / 디렉토리 기본 권한 : 777 ) - umask 값
- umask 값이 클수록 보안 강화 및 접근 제한
■ tcp wrapper : 어떤 외부 컴퓨터가 접속되면 접속 인가 여부를 점검해서 인가된 경우에는 접속이 허용되고, 그 반대의 경우에는 거부할 수 있는 접근제어 유틸리티 (3-way handshake 를 통해 확인함)
■ 간트 차트(Gantt Chart) : 각 작업(Task)의 시작과 끝을 시각적으로 보여주는 프로젝트 관리 도구 (막대 도표)
- 프로젝트 소작업의 시간 관리 (=시간선 차트, Time-Line)
- CPM(Critical Path Method) 네트워크로부터 작성 가능 : 우선순위 및 순서 도출하여 생성
- 자원 배치 계획에 유용하게 사용됨
- 수평 막대의 길이는 각 작업의 기간을 나타냄
■ CPM(Critical Path Method)
- 프로젝트 내에서 각 작업이 수행되는 시간과 각 작업 사이의 관계 파악 가능
- 효과적인 프로젝트의 통제 가능, 경영층의 과학적인 의사 결정을 지원
■ SAN(Storage Area Network)
- 고속 전송, 장거리 연결, 멀티 프로토콜 기능을 지원하는 네트워크 기반 저장 시스템
-여러 개의 저장장치나 백업 장비를 단일화 시스템으로 통합하여 관리 가능
■ SDS(Software Defined Storage)
- 소프트웨어(Software)로 규정(Defined)하는 데이터 스토리지(Storage) 체계
- 서버 가상화와 유사한 원리
■ SDN(Software Defined Networking)
- 하드웨어에 의존하는 네트워크 체계에서 SW로 제어하기 위해 개발됨
- 펌웨어 업그레이드를 통해 사용자의 직접적인 데이터 전송 경로 관리 가능
■ DAS (Direct Attached Storage) : 서버에 연결된 저장장치
- 하드디스크와 같은 데이터 저장장치를 호스트버스 어댑터에 직접 연결하는 방식
- 저장장치와 호스트 기기 사이에 네트워크 디바이스 없이 직접 연결하는 방식
- 서버를 통하지 않고 파일에 직접 접근X (가능한 건 NAS(Network Attached Storage))
■ 고가용성 솔루션(HACMP)
- 공유 디스크를 중심으로 클러스터링으로 엮어 다수의 시스템을 동시에 연결 => 안정성 高
- 2개의 서버를 연결하는 것으로 2개의 시스템이 각각 업무를 수행하도록 구현
■ Secure 코딩에서 입력 데이터의 보안 약점 특징
- 자원 삽입 : 사용자가 시스템에 입력한 데이터로 인해 시스템 자원을 과도하게 사용하는 상태를 유도 => 자원 과부하 발생
- SQL 삽입 : 사용자의 입력 값 등 외부 입력 값이 SQL 쿼리에 삽입되어 공격
- 크로스사이트 스크립트(XSS) : 검증되지 않은 외부 입력 값에 의해 브라우저에서 악성 코드가 실행되는 공격
- 운영체제 명령어 삽입 : 운영체제 명령어 파라미터로 사용자 입력 값을 사용하여 악성 명령어가 실행되는 공격
■ 스택가드(Stack guide): 복귀주소와 변수 사이 특정값이 변경될 떄, 오버플로우 상태로 가정하여 프로그램 실행을 중단
■ Map-Reduce : Google에 의해 고안된 대용량 데이터 처리기술
■ 하둡(Hadoop) : 오픈 소스를 기반으로 한 분산 컴퓨팅 플랫폼 (대용량 경우, 스쿱(Sqoop) 도구 이용)
■ Vaporware(증기웨어) : 계획은 발표되었으나 실제 배포되지않고 있는 SW
■ CMM (Capability Maturity Model) , CMMI (Capability Maturity Model Integration)
- 초기 단계 → 관리 단계 → 정의 단계→ 정량적 관리 단계 → 최적 단계
★암기 Tip★ (초)(장)(관)(리)해 (최)준
- CMMI(발전된 CMM) : 5단계 / SPICE(유럽) : 6단계
■ Authentication(인증, 어센티케이션): 사용자가 본인이 맞는지 (ex. ID, PW 입력하는 과정)
■ Authorization (인가, 어서리제이션 ): 인증된 사용자가 특정 권한을 가졌는지
■ 접근 제어 방법
-Mandatory Access Control(강제 접근통제): 보안 등급을 기준으로 접근 권한을 부여하는 방식
-User Access Control(사용자 접근통제): 관리자 수준의 권한이 필요할 때, 사용자에게 알려 제어하는 방식
-Discretionary Access Control(임의 접근통제): 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식
-Data-Label Access Control(자료별 접근통제): 데이터의 보안 레벨을 기준으로 읽기 및 쓰기 권한을 결정하는 방식
■ 접근 제어 모델
- Bell-Lapadula(BLP) 기밀성 모델: 기밀성 보호에 초점 / 비밀 노출 방지가 중요 / '읽기 하향, 쓰기 상향 원칙' (EX. 군사, 보안)
- Clark-Wilson 무결성 모델: 무결성 보호에 초점 / 정보 변조 방지가 중요 (EX. 금융, 회계)
- Chinese Wall 모델: 경쟁사 정보에는 접근 못하게 제한 / 내부자의 정보 남용 방지
■ 접근통제 정책 종류
-임의적 접근통제(DAX)
-강제적 접근통제(MAC)
-역할 기반 접근통제(RBAC)
■ Salt
-동일한 패스워드라도 서로 다른 암호 값으로 저장되도록 추가되는 랜덤 값
-암호화 과정에서 해시 충돌 및 사전 공격을 방지하는 역할 (암호화 알고리즘)
■ Piconet
-UWB 또는 블루투스 기술을 사용하여 여러 개의 독립된 통신장치가 서로 통신망을 형성하는 무선 네트워크 기술
■ 탐지 시스템
(1) 침입 탐지 시스템(IDS, Intrusion Detection System)
- 시스템이나 네트워크에서 발생하는 의심스러운 활동을 탐지하는 보안 시스템
- HIDS(Host-Based Intrusion Detection): 호스트에서 발생한 이상 활동을 모니터링 (ex. 사용자 계정 추적)
- NIDS(Network-Based Intrusion Detection): 네트워크 트래픽을 분석하여 침입 탐지 (ex. Snort)
(2) 이상 탐지 시스템(Anomaly Detection)
- 이미 발견되지 않은 새로운 공격 패턴을 탐지하기 위해 사용
- 정상적인 활동 패턴을 학습하고, 이와 다른 패턴을 감지하여 이상을 탐지하는 시스템
- 장점: 새로운 공격 탐지 가능 / 단점 : 오탐 발생 가능
(3) 시그니처 기반 탐지 시스템(Signature-Based Detection)
- 네트워크 패킷을 분석하여 공격 패턴(시그니처)를 데이터와 비교하여 침입을 탐지
- 장점: 높은 정확도 / 단점 : 새로운 공격 탐지 어려움
(4) 오용 탐지 기법(Misuse Detection) : 이미 발견되고 정립된 공격 패턴을 입력해두었다가 탐지 및 차단
■ 사용자의 인증 유형
- 지식 (Knowledge) : 알고 있는 것 ( 예: 패스워드, Pin, 패턴)
- 소유 (Possession) : 가지고 있는 것 ( 예: . 토큰, 스마트 카드, QR)
- 행위 (Inherence) : 수행 하는 것 ( 예: 서명, 움직임, 서명)
- 위치 (Location): 사용자가 특정 지역에 있어야만 인증이 이루어지거나 허용되는 경우 (예: IP 기반 위치 확인)
- 시간 (Time): 특정 시간대에만 인증이 허용되는 경우
■ 임계경로의 소요기일: 모든 소요기일 계산 후, 가장 오래 걸린 기일
■ 정보 보안 요소
- 기밀성(Confidentiality): 읽지 못한다
- 부인방지(NonRepudiation): 증거 남긴다
- 가용성(Availability): 항상 사용 가능
- 무결성(Integrity): 수정 불가능
★암기 Tip★ (기)(무)리뷰에서 (부인)이 (가)짜라는 영화가 나왔음
■ BaaS(서비스형 블록체인): 클라우드 제공업체가 블록체인 네트워크를 호스팅하고 관리하는 서비스 (예. AWS)
■ 프로젝트 비용 산정 기법
(1) 하향식
- 전문가 감정 기법 : 조직 내에 있는 경험 많은 두 명 이상의 전문가에게 비용 산정을 의뢰하는 기법 (나때는~)
- 델파이 기법 : 전문가 감정 기법의 주관적 편견을 보완하기 위해 많은 전문가의 의견을 종합 (여러 전문가)
(2) 상향식
- LOC 기법(Line Of Code) : 원시 코드 라인 수 기법으로서 원시 코드 라인 수의 비관치 낙관치 기대치를 측정하여 산정하는 기법
- 개발 단계별 인월수 기법 : LOC를 보완하기 위한 기법, 필요 노력을 생명 주기의 각 단계별로 선정
(3) 수학적
- COCOMO : 보헴이 제안한 것으로 LOC에 의한 비용 산정 기법
- Putnam : Rayleigh-Norden 곡선의 노력 분포도 이용 >> 자동화 추정 도구 : SLIM
★암기 Tip★ 훈남(Putnam)이 노력(노력분포도) 해서 슬림(SLIM) 해졌네
- Function-Point(FP) : 요구기능별 가중치 부여하여 점수계산
■ 상향식 비용 산정 기법 중 LOC(원시 코드 라인 수) 기법에서 예측치를 구하기 위해 사용하는 항목 : 낙관치, 비관치, 기대치
■ COCOMO Model ( COnstructive COst MOdel ) : sw 개발비용 추정하는데 사용됨
- Orgranic: 조직형 / 5만 라인 이하의 소프트웨어 개발 (소규모 프로젝트)
- Semi-Detached: 반분리형 / 30라인 이하 (중간 규모 프로젝트)
- Embedded: 내장형 / 30만 라인 이상 (대규모 프로젝트)
■ 내부 게이트웨이 프로토콜(IGP, Interior Gateway Protocol) ↔ EGP (예. BGP)
(1) 거리 벡터 라우팅 프로토콜
- Bellman-Ford 알고리즘 사용
- RIP 프로토콜(최대 홉 수 15)
- 인접 라우터와 주기적으로 정보 교환
(2) 링크 상태 라우팅 프로토콜
- Dijkstra 알고리즘 사용
- OSPF 프로토콜(홉 수 제한 없음)
- 최단 경로, 최소 지연, 최대 처리량
■ SPICE : 소프트웨어 평가 국제표준
■ WPA(Wi-Fi Protected Access): Wi-Fi에서 제정한 무선 랜(WLAN) 인증 및 암호화 관련 표준
■ Data Mining : 변수 사이의 상호관례를 규명하여 일정한 패턴 찾는 빅데이터 분석 기술
■ 스마트 그리드 : 전력망을 지능화, 고도화하여 전력서비스 품질↑, 에너지 이용효율 ↑
■ wtmp : 리눅스 시스템에서 사용자의 성공한 로그인/로그아웃 정보 기록
■ BitLocker (빅로커) : Windows 전용 볼륨 암호화 기능 (TRM, AES-128 알고리즘 사용)
■ Mesh Network : 기존 무선 랜의 한계 극복 = "그물" (특수목적)
■ Mashup : 웹에서 제공하는 정보 및 서비스를 이용하여 새로운 소프트웨어나 서비스, 데이터베이스 등을 만드는 기술
■ 올조인 (AllJoyn) : 오픈소스 기반의 사물인터넷(IoT) 플랫폼, 서로 다른 기기들이 표준화된 플랫폼을 이용하여 서로 제어 가능
■ OWASP (Open Web Application Security Project) : 웹을 통한 보안 취약점 등을 연구하는 곳
■ Samba(삼바) : 서버/클라이언트 프로토콜 기반의 프리웨어 (오픈소스) 프로그램 >> 기능: 파일, 프린터 공유
■ 스크랩 프로그램
- 정형 데이터 : ETL, ETP, API, Sqoop, DBtoDB
- 비정형 데이터 : 크롤링, Open API, RSS, Chukwa, Kafka
- 반정형 데이터 : Flume, Scribe, 스트리밍
■ Scratch : 교육용 프로그래밍 언어
■ N-Screen : 여러 기기에서 원하는 콘텐츠를 자유롭게 이용
■ 프로젝트 관리 유형 : 일정, 위험, 품질, 비용, 인력 관리 (보안 관리는 X)
■ 닷넷 프레임워크(.NET Framework) : 마이크로소프트사 , 공통 언어 런타임(CLR)
'CodingDiary > 자격증공부' 카테고리의 다른 글
| 정보처리기사 실기 오답노트 (0) | 2025.03.25 |
|---|---|
| SQL 개발자 자격증 공부 (0) | 2025.03.05 |